SQLで以下のような3つのグループの重複や重複無しの数値を集計する方法について紹介します
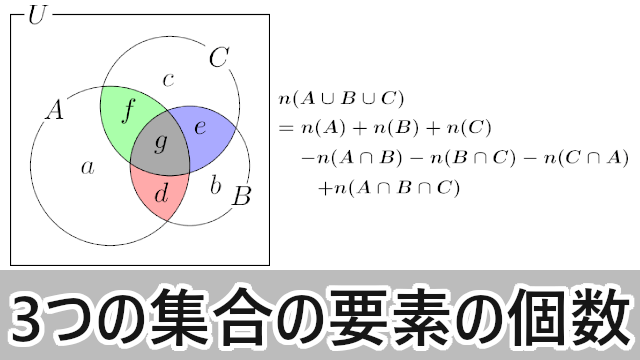
-- 1. aとbで重複 SELECT COUNT(*) AS ab_overlap FROM a JOIN b ON a.user_id = b.user_id LEFT JOIN c ON a.user_id = c.user_id WHERE c.user_id IS NULL; -- 2. aとcで重複 SELECT COUNT(*) AS ac_overlap FROM a JOIN c ON a.user_id = c.user_id LEFT JOIN b ON a.user_id = b.user_id WHERE b.user_id IS NULL; -- 3. bとcで重複 SELECT COUNT(*) AS bc_overlap FROM b JOIN c ON b.user_id = c.user_id LEFT JOIN a ON b.user_id = a.user_id WHERE a.user_id IS NULL; -- 4. a、b、cすべてで重複 SELECT COUNT(*) AS abc_overlap FROM a JOIN b ON a.user_id = b.user_id JOIN c ON a.user_id = c.user_id; -- 5. aのみ SELECT COUNT(*) AS only_a FROM a LEFT JOIN b ON a.user_id = b.user_id LEFT JOIN c ON a.user_id = c.user_id WHERE b.user_id IS NULL AND c.user_id IS NULL; -- 6. bのみ SELECT COUNT(*) AS only_b FROM b LEFT JOIN a ON b.user_id = a.user_id LEFT JOIN c ON b.user_id = c.user_id WHERE a.user_id IS NULL AND c.user_id IS NULL; -- 7. cのみ SELECT COUNT(*) AS only_c FROM c LEFT JOIN a ON c.user_id = a.user_id LEFT JOIN b ON c.user_id = b.user_id WHERE a.user_id IS NULL AND b.user_id IS NULL;

コメント